ghh2001
G Han
Recently Published





NonTechnicalReport Beverage
For ABC Beverage company, my leadership has told me that new regulations are requiring us to understand our manufacturing process, the predictive factors and be able to report to them our predictive model of PH. This is the NON-TECHNICAL part
PH Prediction in Beverage Manufacture-Proj 2
Project description: In ABC Beverage company, my leadership has told me that new regulations are requiring us to understand our manufacturing process, the predictive factors and be able to report to them our predictive model of PH.

Time Series Forecasting Hw2
A few datasets are utilized, in HA book chapter 3.1, to test the necessity of box-cox transformation, Seasonal naive model, and a few other common mathematical transformation methods in time series.
Glass Data Preprocessing Issue
The UC ML glass identification database was used to examine the issue of data procrocessing and addressing the overfitting issue, as a necessary step for future machine learning need.



Trees and Rules KJ8.1-8.3
We used a few simulated dataset to demonstrate the nuts and bolts of a few trees and rules machine learning algorithm, random forest, cforest, gbm, cubist. We also looked into details the issues of correlated variables' impact on model, the impact of different bagging and learning rates, and the variable granularity.
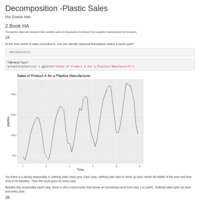
Trees and Rules
Using the chemical manufacturing process database (K&J 7.5), applies a few tree based system to decide the optimal model and compare them

Non Linear Regression KJ7.5Chemical Manufacture
This project uses data imputation, data splitting, and pre-processing steps , and train several nonlinear regression models, on the K&J 7.5 chemical manufacturing data set. The models used included KNN, SVM, MARS, NN. Models performance were done.

K&J7.2
Friedman (1991) introduced several benchmark data sets create by simulation. This document uses a few models to evaluate it (KNN, MARS,SVM,MARS)

Permeability Prediction
PLS model tuning is used to determine the permeability of potential drug compounds.
LinearRegression Chemical Manufacturing Process
Using the data of chemical manufacturing process, the objective is to understand the relationship between biological measurements of the raw materials (predictors), measurements of the manufacturing process (predictors), and the response of product yield (outcome).
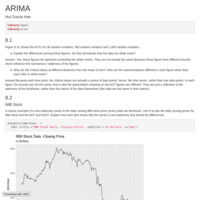
Document
ARIMA Model, HA8.1-8.7


Movie Recommend via SVD IBCF UBCF
Research Question:How can I recommend the top 10 movies to certain people (users), based on their history of preference, or on the experience of similar people like them, or some other mechanism?Q Content based filtering, User based filtering, and SVD.

MovieLenseCollaborativeFilteringvsSVD
Content based filtering, User based filtering, and SVD are performed on the movielense data within the recommenderlab package. Their performance is also compared.
Jokes Recomders
This project compares different recommendation systems for certain users, on the jokes they might like. The comparisons are based on users (UBCF) and items (IBCF). Different normalization mechanisms are also compared.
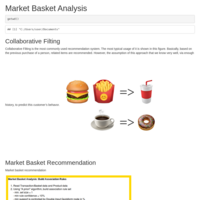


Singular Value Decomposition
This is the singular value decomposition methods for the recommendation system, using movie lense dataset

















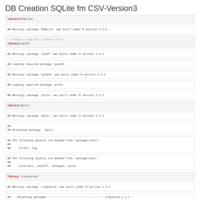
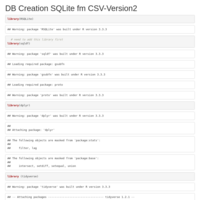
DB Creation SQLite fm CSV-Version2
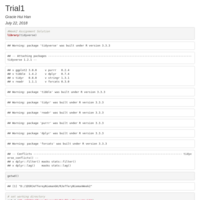
Proj3_607




Week7 607
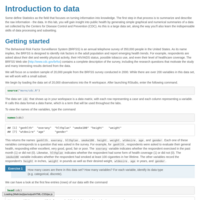
Read Json, HTML, XML data into R



Project1 607
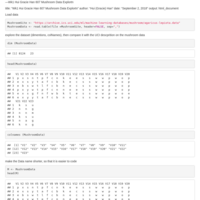
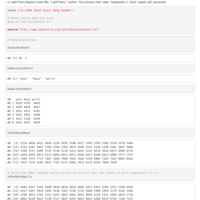
Tournament Data

HomeWork Chap1 - IntroStat
Hui (Gracie) Han Solution